In this article, we will touch on recommendation engines, why it is useful and how Haulio has structured our recommendation engine to better serve our users’ needs.
What is a Recommendation Engine/System?
A recommendation engine is a system that suggests products, services, information to users based on analysis of data. The recommendation can derive from a variety of factors such as the history of the user and the behaviour of similar users.
Pioneered by the likes of Amazon and Netflix, the ability to predict a customer’s needs and provide proactive recommendations based on this understanding, is reshaping how businesses interact with their customers.
In e-commerce, recommendation systems are widely used to suggest similar or popular products on pages that visitors are already looking at.
Recommendation systems are quickly becoming the primary way for users to navigate the e-commerce world, based on their experiences, behaviours, preferences, and interests. Similarly, it has huge potential and applications in the B2B world, especially in supply chain.

The Problem
In a 2010 study conducted by software developer Oracle, businesses are losing out on £1.2bn a year in missed sales opportunities owing to fragmented supply chains. A decade later, not much has changed. Trade is still conducted via highly fragmented stakeholders, each utilising spreadsheets, isolated databases, with a majority still using paper documentation.
This inevitably forms a huge data and asset usage inefficiency. Paired together with an immense rise in global trade demand, it has drastically brewed an intermodal capacity crunch – increased congestions in seaports, shortage of locomotives, handling crew, truck driver, container space and trailers.
The sustainability trend for this part of the supply chain is therefore very apparent and in need for a solution. Through our all-encompassing digital suite of tools and operational systems, Haulio is supporting this trend by innovating the connectivity of haulage stakeholders.
- The Haulage Operations Platform (HOP) is an all-in-one platform for hauliers to manage their trucking jobs, with access to our job pool. From fleet and asset management, to friendly dashboards, Kanban-style job scheduling and real-time job updates, the HOP removes the mundane and makes managing trucking a breeze.
Haulio’s customer portal is built for haulage procurers to manage all their trucking needs, and designed to stay…
To date, Haulio has more than 80% of Singapore’s hauliers on board and have transacted more 250,000 TEUs. However, apart from the job pool and haulage management solutions we provide, we wanted to further improve the efficiency of our hauliers at scale. This had to be done by further enhancing our job pool through recommendation of suitable jobs for hauliers.
Haulio’s Recommendation Engine
Based on more than 3 years of data, we have built a recommendation engine to better serve our hauliers through recommendation of jobs that increase their fleet efficiency.
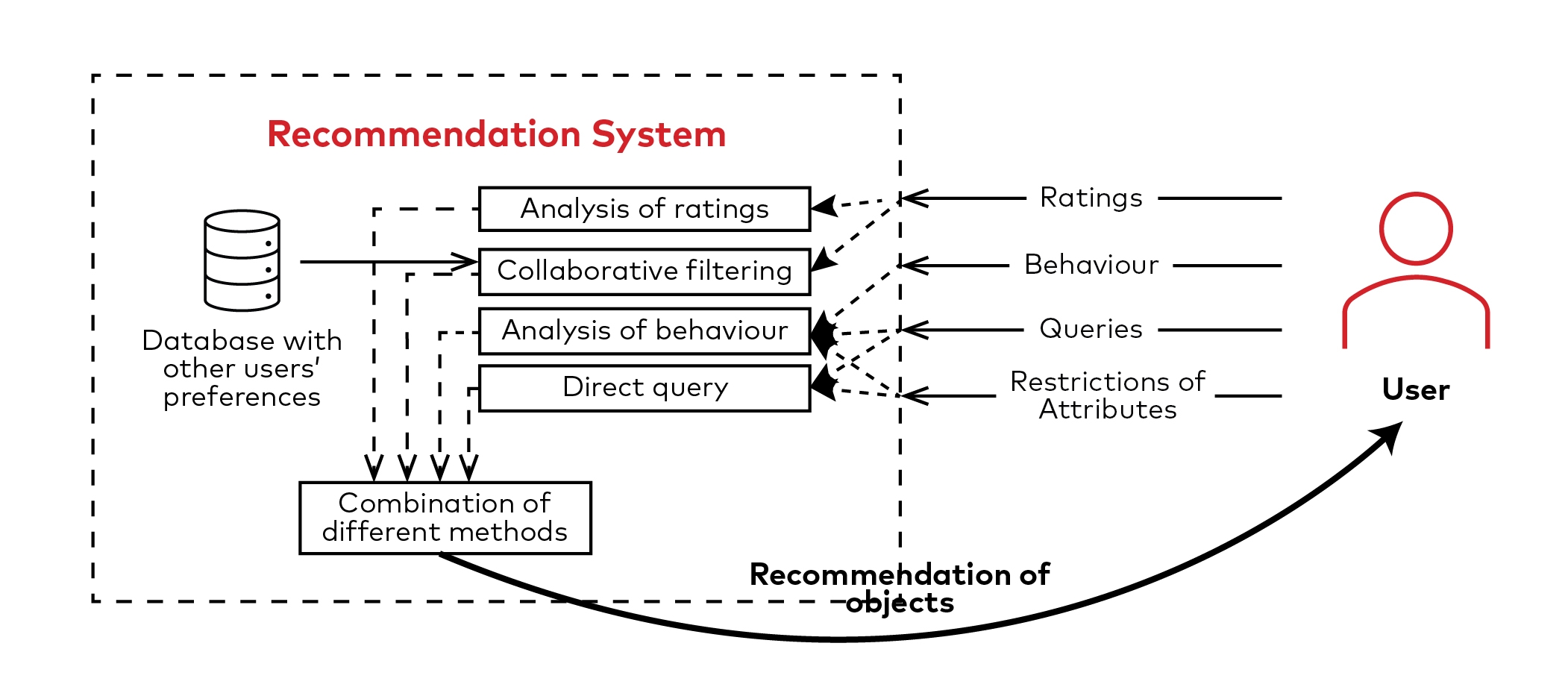
The structure of Haulio’s recommendation engine is based on three key components:
- Past Behaviour
- Based on what users’ historical preference and behavioural observations, we look at the kind of jobs our hauliers usually respond to derive their preference. From there, we can recommend jobs that better fit what they want.
- Interactions from other similar users are also used to derive suggestions. This approach makes recommendations based on other users with similar tastes or situations, which can also introduce some increased variability apart from the usual jobs they take.
- Jobs Taken
- Based on current jobs taken by the trucker, Haulio’s recommendation system recommends suitable jobs to complement it.
- For example, if a trucker has taken more import jobs, Haulio’s recommendation system is able to recommend more export jobs to increase fleet optimisation.
- Similarly, if a trucker is on his way to a container depot, the system can also recommend a job for him to bring back an empty container from the same area.
- Haulio is also partnering with Avantida to provide container street turns with shipping company CMA CGM. Through Haulio’s platform, truckers can digitally request for containers to match their import or export trips, after which the Avantida platform provides an automated connection to the ocean line’s booking system where the request will be processed instantly.
- Overall Fleet Capabilities
- To optimise service delivery, Haulio’s recommendation engine also considers the overall capacity of each haulier’s fleet to prevent them from accepting more jobs than they can handle.
- This prevents Haulio from passing jobs to hauliers who are already sufficiently busy.
Haulio’s Approach
Recommender systems usually make use of either or both collaborative filtering and content-based filtering, as well as other systems such as knowledge-based systems.
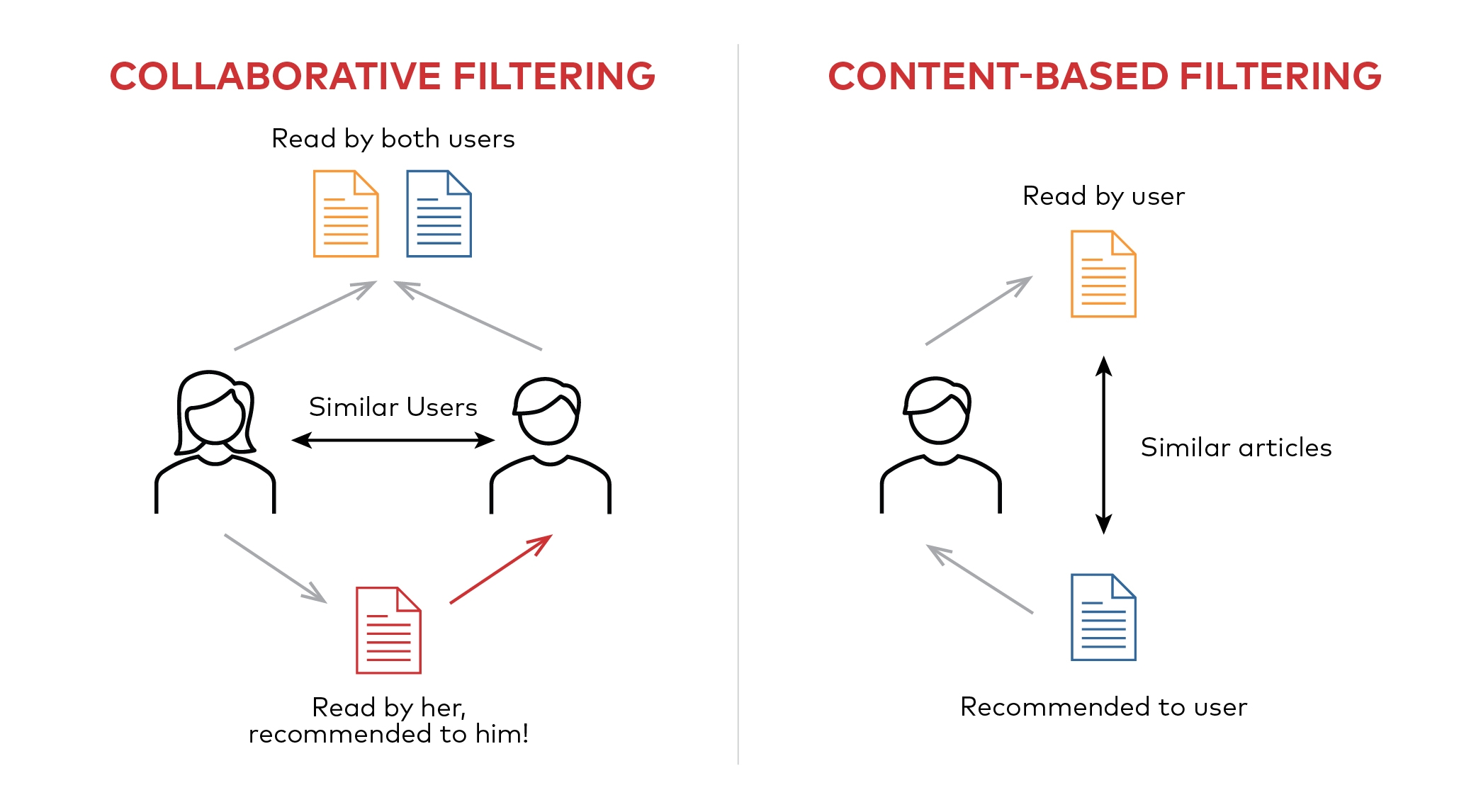
Content-based recommenders attempt to recommend similar items that a given user likes in the past, and do not require a user-item rating matrix. Comparatively, the collaborative filtering recommendation algorithm will try to identify users with the same preferences and recommend items they like.
However, collaborative filtering only recommends based on the user’s rating of the product, which may result in the problem of a cold start if there is a lack of such data.
“The cold start problem occurs when the system cannot draw any inferences for users or items about which it has not yet gathered sufficient information.”
Although the content-based approach needs additional information that depends on items and user preferences, it does not require too many user feedback or massive records. In other words, only one user is needed to complete the recommendation function and generate a recommendation list. As such, we have chosen to adopt the content-based approach.
The Content-based Approach
Content-based recommender systems are mainly used where the item is either a document or a text used to describe an item. Thus, text mining methods play an important role in content-based recommender systems.
In Haulio’s case, the algorithm is also applied to other recommended fields, such as finding the best haulage jobs for a haulier, or finding the best hauliers for a job.
The CB algorithm is made up of three parts:
- Content Analysis: Characteristic attributes for each item are extracted, that is, the description operation of structured items. The corresponding processing process is called Content Analysis.
- Profile Learning: Using item feature data that a user likes (or dislikes) in the past to learn the user’s preference profile. The corresponding processing process is called Profile Learning (or Feature Learning).
- Recommendation Generation: By comparing the user profile obtained in the previous step to the characteristics of the feature item, it is sufficient for the user to recommend a set of items with the most relevance. The corresponding processing process is called Filtering Component.
Note:
We will not go into detail for the respective methods and algorithms, as the purpose of the article is to outline Haulio’s approach to building our recommendation engine.
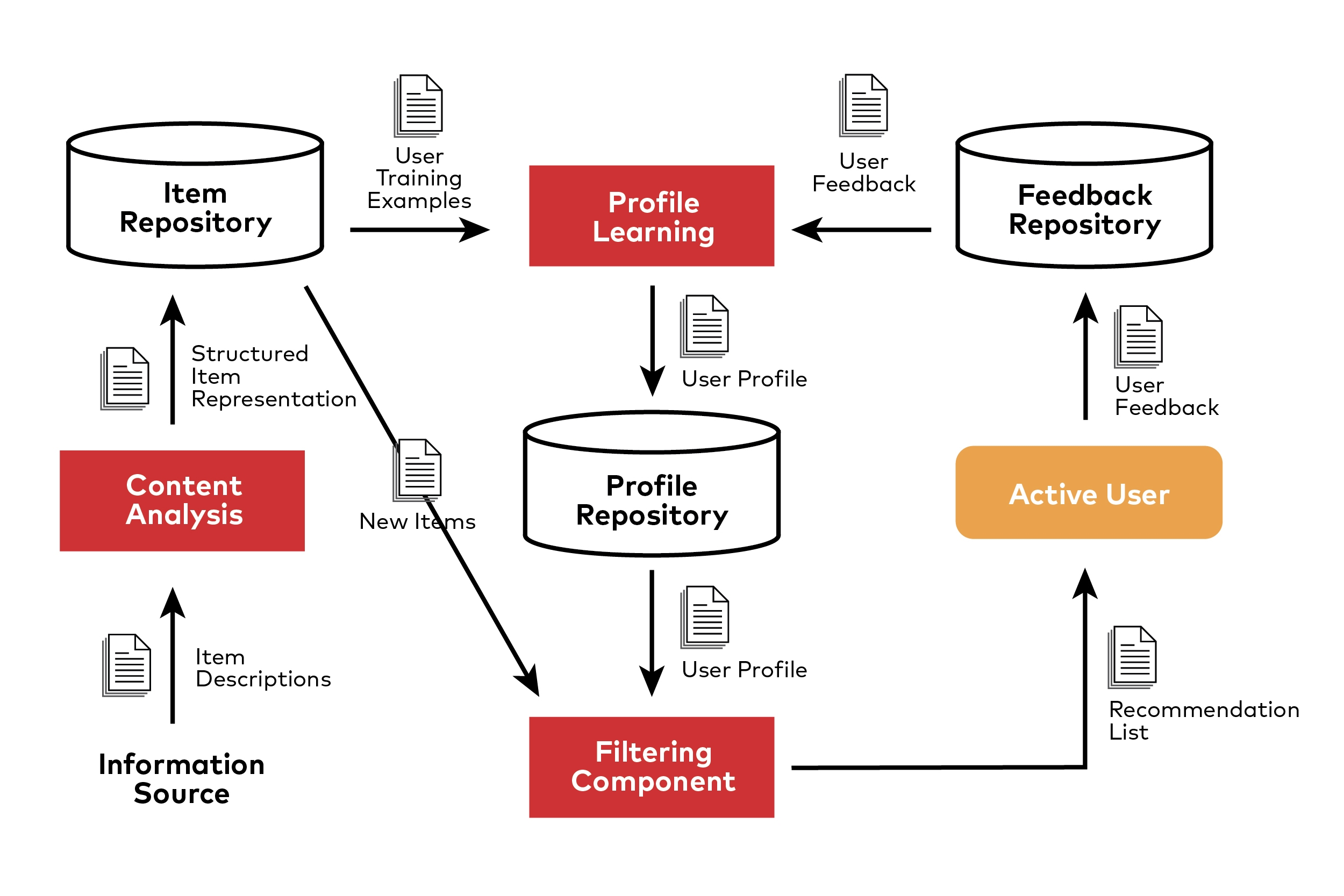
Step 1. Content Analysis
Here, raw data is pre-processed to extract featured information. The method used for the extraction of item or job feature attributes mainly includes the processing of numeric data and non-numeric data. The main processing methods are:
- Normalization of numerical data
- Binarization of numerical data
- Non-numeric data word bag method is converted into feature vector
- TF-IDF
Step 2. Profile Learning
This step is specifically designed for the user. It receives the pre-processed information from the content analyzer and generalizes them to construct the user preferences.
Assuming that haulier h has shown preference for some jobs but not others, then the process is to build a discriminant model based on these preferences of haulier h in the past, and finally judge whether haulier h will like a potential new job.
This is therefore also a typical probabilistic modelling problem. In theory, machine learning classification algorithms can be used to solve the required discriminant model.
Commonly used algorithms are:
- Nearest neighbor method (K-Nearest Neighbor – KNN)
- Offline classification algorithm (Linear Classifier – LC)
- Naive Bayes (NB)
Step 3. Recommendation Generation
This is the final part that finds the relevant items based on the user profile and recommends them to the user. Here, the Filtering Component takes all the inputs and generates the list of recommendations for each user.
Advantages & Disadvantages of Content-Based Recommenders
As described before, a key advantage of content-based recommenders is its user-independence – in the process of building the model, only the current user’s information needs to be considered.
Content-based recommenders are also largely transparent – By explicitly listing the content features or descriptions that make items appear in the recommendation list, we can clearly explain how the recommendation system works.
Another key advantage is also the ability to recommend without feedback. As such, new jobs can be recommended to hauliers, for which no ratings are available yet.
In building our recommender, it is also important to consider the limitations of content-based recommenders.
With content-based recommenders, feature extraction is difficult: the number and types of features related to the recommended objects are limited, and rely largely on domain knowledge.
The algorithm also runs the risk of overspecialization: With CB, the recommendation result is similar to a previously accepted job. If a user only accepts such jobs, then it is impossible for the recommendation system to find that this haulier may also like other jobs. To increase variability of recommended jobs, collaborative filtering can also be used to predict and recommend items based on similar users’ preferences.
Lastly, the CB algorithm needs to rely on the specific haulier’s historical data, it may not be possible to generate a more reliable recommendation for new hauliers.
Future Roadmap
Currently, Haulio’s recommendation workflow is based largely on completed job transactions.
The more rightful workflow should begin as the engine proposes some hauliers and offer the jobs to them. The haulier should have an option to indicate if they like or dislike the recommended jobs by accepting, rejecting or ignoring the job accordingly. This indication serves as a feedback loop to improve the recommendation engine positively (illustrated in orange below).
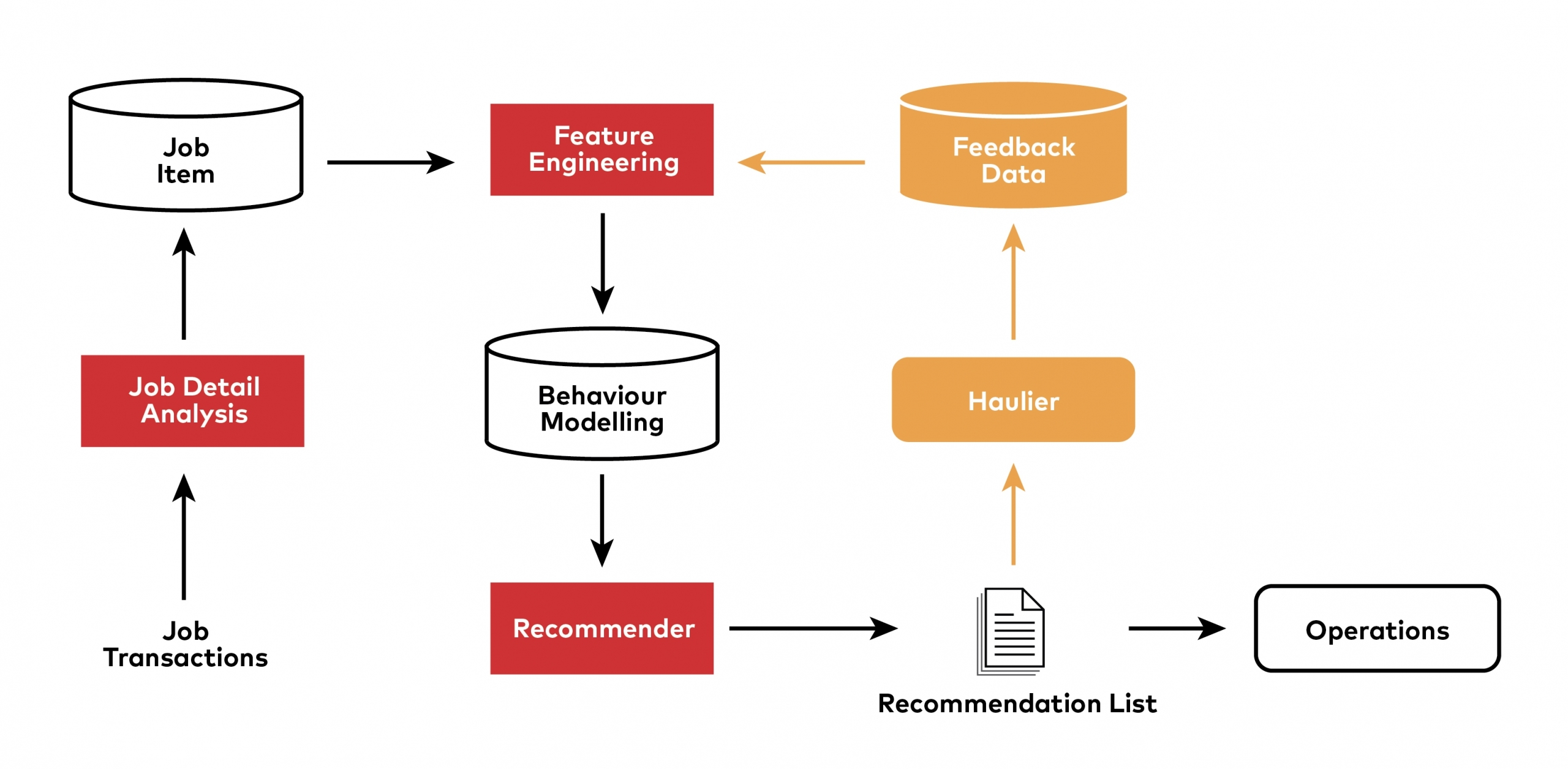
In our current implementation and operational model, the explicit feedback doesn’t exist. As such, future improvements to our recommendation engine includes building the explicit feedback into the process.
Keen to find out more? Contact us now!
Fill up the form below and we’ll get in touch shortly!